1. Giới thiệu
Trong thời đại AI phát triển mạnh mẽ, việc nhận diện hành động trong video có nhiều ứng dụng quan trọng như:
- Giám sát an ninh: Phát hiện các hành vi đáng ngờ trong camera an ninh.
- Phân tích thể thao: Nhận diện động tác của vận động viên.
- Hỗ trợ y tế: Giám sát cử động của bệnh nhân.
Một trong những mô hình phổ biến để xử lý bài toán này là LRCN (Long-term Recurrent Convolutional Networks), kết hợp CNN để trích xuất đặc trưng hình ảnh và LSTM để xử lý chuỗi thời gian.
2. Chuẩn bị môi trường
Trước tiên, hãy cài đặt các thư viện cần thiết:
!pip install pafy youtube-dl moviepy pytube tensorflowImport các thư viện quan trọng:
import os
import cv2
import pafy
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from tensorflow.keras.layers import *
from tensorflow.keras.models import Sequential3. Tải và xử lý dữ liệu
Bộ dữ liệu UCF-50 chứa 50 loại hành động như chạy, nhảy, bơi, nâng tạ…
Tải dữ liệu:
!wget --no-check-certificate https://www.crcv.ucf.edu/data/UCF50.rar
!unrar x UCF50.rarSau khi tải về, chúng ta chia dữ liệu thành tập huấn luyện, kiểm tra và xác thực.
Ví dụ về một số khung hình trong tập dữ liệu:

4. Xây dựng mô hình LRCN
Mô hình LRCN kết hợp CNN và LSTM để nhận diện hành động trong video:
model = Sequential()
model.add(TimeDistributed(Conv2D(32, (3,3), activation='relu'), input_shape=(None, 64, 64, 3)))
model.add(TimeDistributed(MaxPooling2D((2,2))))
model.add(TimeDistributed(Flatten()))
model.add(LSTM(64, return_sequences=False))
model.add(Dense(50, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])Mô hình sẽ học được các đặc trưng không gian từ CNN và phân tích sự thay đổi theo thời gian bằng LSTM.
Kiến trúc mô hình:

5. Huấn luyện mô hình
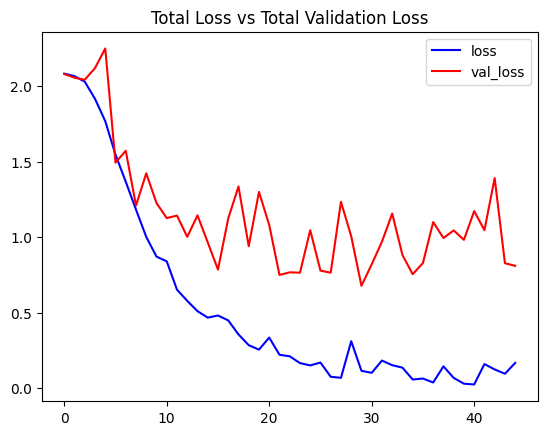
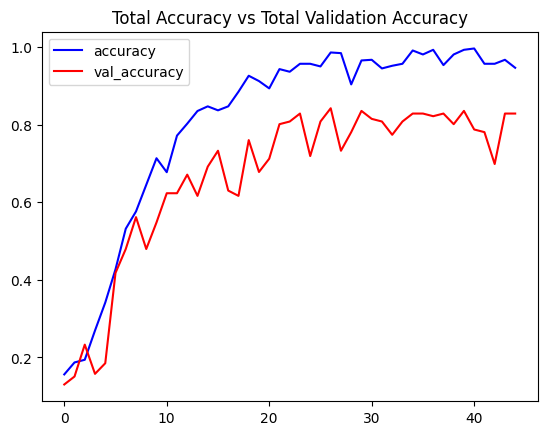
history = model.fit(X_train, y_train, validation_data=(X_val, y_val), epochs=20, batch_size=16)Sau khi huấn luyện, ta kiểm tra độ chính xác:
score = model.evaluate(X_test, y_test)
print(f'Accuracy: {score[1]*100:.2f}%')Kết quả huấn luyện:
6. Kiểm tra mô hình với video thực tế
Sau khi mô hình đã được huấn luyện, ta có thể thử nghiệm với video mới bằng cách sử dụng OpenCV để trích xuất khung hình và dự đoán hành động.
def predict_video(video_path, model):
cap = cv2.VideoCapture(video_path)
frames = []
while cap.isOpened():
ret, frame = cap.read()
if not ret:
break
frame = cv2.resize(frame, (64, 64))
frames.append(frame)
cap.release()
frames = np.array(frames) / 255.0
prediction = model.predict(np.expand_dims(frames, axis=0))
return np.argmax(prediction)Ví dụ video test:

Dự đoán:

7. Cải tiến và mở rộng
Mô hình LRCN có thể được cải tiến bằng cách:
- Thay thế CNN backbone bằng ResNet hoặc EfficientNet để trích xuất đặc trưng tốt hơn.
- Sử dụng Attention Mechanism để giúp mô hình tập trung vào vùng quan trọng của ảnh.
- Thay thế LSTM bằng Transformer để tận dụng khả năng mô hình hóa ngữ cảnh dài hơn.
- Tăng cường dữ liệu bằng cách sử dụng OpenCV để biến đổi video (xoay, thay đổi ánh sáng,…).
8. Kết luận
LRCN là một phương pháp mạnh mẽ trong nhận diện hành động video. Tuy nhiên, để ứng dụng thực tế hiệu quả, chúng ta cần kết hợp với các kiến trúc tiên tiến hơn như:
- I3D (Inflated 3D ConvNets)
- SlowFast Networks
- Video Swin Transformer
📌 Nếu bạn muốn xem toàn bộ mã nguồn, hãy tham khảo trong notebook đi kèm!
link: https://colab.research.google.com/drive/1q4Y02PI4ftrO-AyqVW1hdORyp8NuxNfq?usp=sharing
Tham gia group fb: Helios Community – Cộng đồng về AI, học tập & ứng dụng để nhận thêm nhiều project khác